Группировка строк без заливки
Порою нам в работе с Excel приходится выполнять не самые веселые вещи, которые казалось бы и не составляют особого труда, но занимают достаточно много времени. И это действительно «напрягает», особенно когда горят сроки сдачи чего-нибудь или когда дел невпроворот. К одному из таких занятий я отношу «наведение красоты» в таблицах в виде группировки строк/столбцов или другими словами – создания структуры. В каких случаях с этим сталкивался я? Вот, наверное, основные из них:
Необходимо сделать так, чтобы сводной таблицей мог пользоваться даже тот человек, который не имеет представления что это такое, и чтобы при этих действиях таблица не «залазила» на стоящие внизу/справа данные. Необходимо взять данные из присланного HTML файла, где промежуточные итоги окрашены особым цветом, и перенести это всё в Excel, сохранив структуру. Необходимо оперативно привести в порядок полученный от кого-либо файлик с табличкой, тянущейся на многие и многие строки вниз. Необходимо отформатировать выгруженные данные из 1С, которые были сохранены без структуры. Итак, понимание того, что нужно сделать есть, осталось только понять, как это всё реализовать. Для этого предлагаю расписать алгоритм последовательности действий нашей программы. За основу возьмём пример группировки строк без заливки, как наиболее часто встречающийся:
Программа пробегает по каждой ячейке выделенного пользователем диапазона Если ячейка стоит в начале выделения или это первая ячейка без заливки после ячеек с заливкой, то запоминаем ее адрес для дальнейшей группировки. Если достигнута последняя ячейка выделения или ячейка с заливкой, перед которой была(-и) ячейка без заливки, то применяем группировку к строкам от самой первой, адрес которой мы запомнили, до последней. В общем, алгоритм не особо замысловатый, поэтому дело за самим кодом :)) Назовём нашу процедуру, которая будет группировать строки без заливки соответствующим образом – GroupCellsWithoutFill. Все дальнейшие операции будем проводить в ней.
Итак, для начала, необходимо считать выделенный диапазон и организовать цикл, благодаря которому мы сможем считать информацию о заливке каждой из ячеек выделения.
Sub GroupCellsWithoutFill()
Dim rngWhole As Range
Dim rngArea As Range
Dim rngCell As Range
Set rngWhole = Selection
For Each rngArea In rngWhole.Areas
For Each rngCell In Application.Index(rngArea, 0, 1)
'//Main part of code goes here
Next rngCell
Next rngArea
'//Releasing memory
Set rngWhole = Nothing
Set rngArea = Nothing
Set rngCell = Nothing
End Sub
Обратите внимание, как здесь написан цикл нижнего уровня. Можно было бы написать For Each rngCell In rngArea, однако давайте представим, что пользователь по ошибке выделил два или три столбца. И тогда программе пришлось бы тратить в два или три раза больше итераций на то, чтобы проверить цвет каждой ячейки. Однако в вышеприведенном коде указано, что необходимо брать лишь ячейку из ПЕРВОГО СТОЛБЦА ВЫДЕЛЕНИЯ. Таким образом, пользователь может выбрать и всю таблицу целиком – код всё равно будет анализировать лишь ячейку, которая будет в крайнем левом столбце выделения, что вполне резонно.
Описав общую структуру циклов, мы двигаемся вглубь. При каком условии мы будем группировать строки? – При условии того, что это ЛИБО последняя ячейка области выделения, ЛИБО же это последняя ячейка без заливки, после которой идёт ячейка с заливкой.
На данном этапе нам необходимо понимать 3 вещи:
- Какова первая строка незакрашенной области
- Какова последняя строка незакрашенной области
- Находимся ли мы на строке внутри незакрашенной области, либо же снаружи.
Для обозначения первой строки неокрашенного диапазона введем переменную lUpper, а для последней, соответственно lLower. Для того, чтобы понимать двигаемся ли мы в данный момент внутри незакрашенного диапазона (открыта ли группа), или же вне его (группа закрыта), введем еще одну переменную bGroupOpen.
Dim lUpper As Long
Dim lLower As Long
Dim bGroupOpen As Boolean
bGroupOpen = False
Dim lUpper As Long
Dim lLower As Long
Dim bGroupOpen As Boolean
bGroupOpen = False
Так как выделение может содержать несколько областей, то логично предположить, что первая и последняя строка должны ограничиваться как минимум границами областей, а не всего выделения. Поэтому будем начальную строку приравнять к первой строке каждой конкретной области.
For Each rngArea In rngWhole.Areas
lUpper = rngArea.Row
lLower = lUpper
For Each rngCell In Application.Index(rngArea, 0, 1)
'//Main part of code goes here
Next rngCell
Next rngArea
For Each rngArea In rngWhole.Areas
lUpper = rngArea.Row
lLower = lUpper
For Each rngCell In Application.Index(rngArea, 0, 1)
'//Main part of code goes here
Next rngCell
Next rngArea
При прохождении по самим ячейкам внутри каждой области, у нас будет лишь два различных случая – когда заливка ячейки удовлетворяет условиям (в нашем случае – отсутствует), или не удовлетворяет.
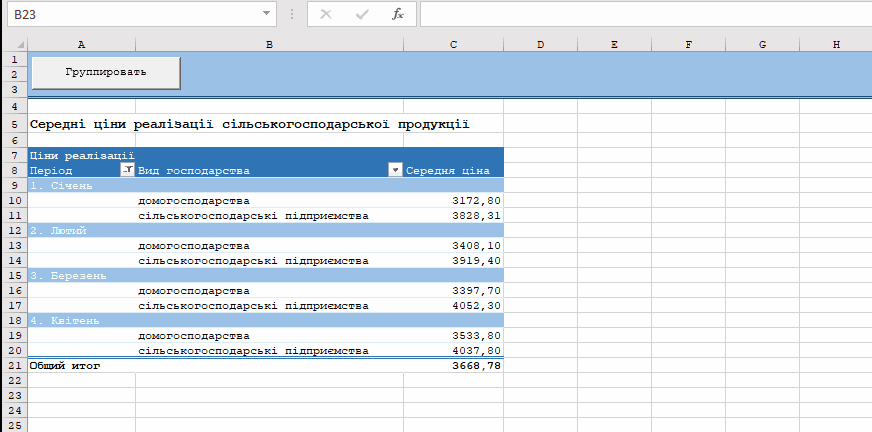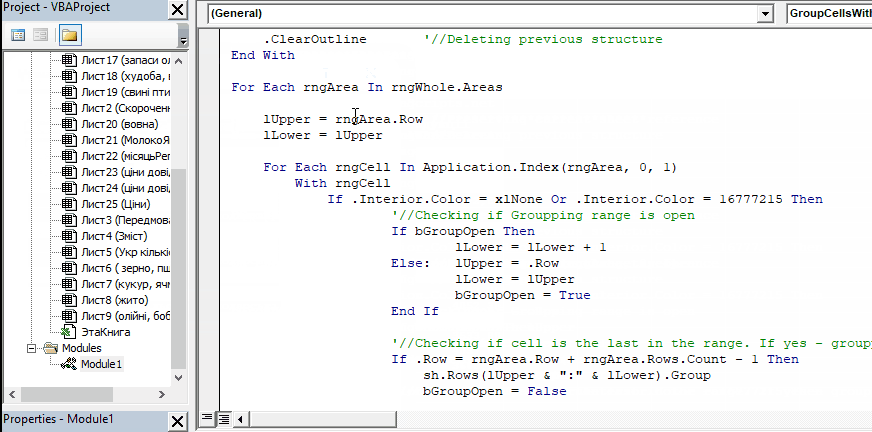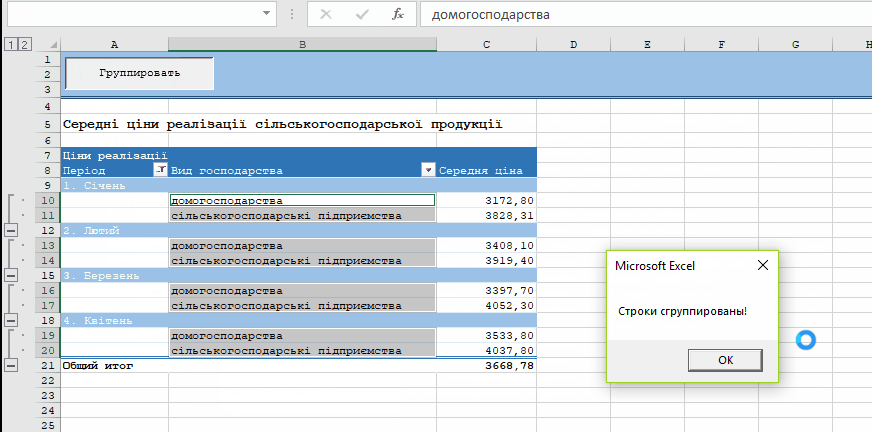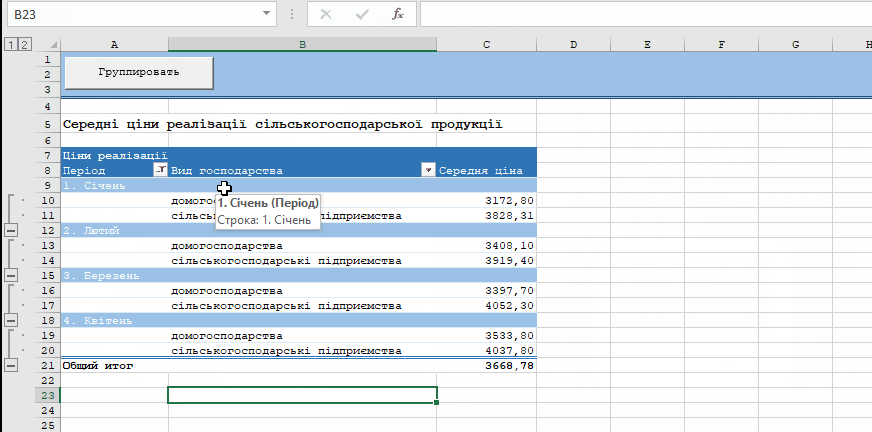
With rngCell
If .Interior.Color = xlNone Or .Interior.Color = 16777215 Then
'//Checking if Groupping range is open
If bGroupOpen Then
lLower = lLower + 1
Else: lUpper = .Row
lLower = lUpper
bGroupOpen = True
End If
'//Checking if cell is the last in the range. If yes - groupping the range
If .Row = rngArea.Row + rngArea.Rows.Count - 1 Then
sh.Rows(lUpper & ":" & lLower).Group
bGroupOpen = False
End If
Else
'//Checking if Groupping range is open
If bGroupOpen Then
sh.Rows(lUpper & ":" & lLower).Group
bGroupOpen = False
Else: lLower = .Row
lUpper = lLower
End If
End If
End With
Словами, алгоритм проделывает следующее: если ячейка не имеет заливки, то код проверяет, была ли предыдущая ячейка незакрашенной (If bGroupOpen=True then). Если да, то нижний диапазон сдвигается на одну строку вниз и дальше идет проверка следующей ячейки, если таковая имеется. А если предыдущая ячейка не была закрашенной, то ставится флаг (bGroupOpen=True) о том, что началась группа ячеек без заливки. Если мы добрались до последней ячейки области, то группа закрывается (bGroupOpen=False) и строки группируются.
Если же ячейка имеет заливку, то код проверяет была ли предыдущая ячейка окрашенной. Если да – то строки группируются и группа закрывается. Если предыдущая ячейка не была закрашенной, то просто смещаем значение lLower, lUpper на одну строку вниз.
После всего этого мы получим рабочий код, который будет группировать строки по нужным нам условиям. Однако, применив данную процедуру несколько раз к одному и тому же диапазону, мы заметим, что уровень группировки меняется на более глубокий при каждом запуске процедуры. Поэтому целесообразно перед началом кода удалять имеющуюся (порой даже неправильную) структуру и применять описанную в коде.
With rngWhole
Set sh = .Parent '//Preserving current sheet reference
.ClearOutline '//Deleting previous structure
End With
Пример работы скрипта:
Обернув всю процедуру в конструкцию On Error GoTo ERR_POINT и добавив информационные MsgBox’ы, мы получим готовый код, который вы можете скачать в приложенном файле.